
 Share
Share
2025年8月5日、OpenAIは人工知能コミュニティに大きな衝撃を与える発表を行いました。新たに2つの大規模言語モデル(LLM)「gpt-oss-120b」と「gpt-oss-20b」をリリースしたのです。これは、2019年にGPT-2の「オープンウェイト」モデルを公開して以来、初めての試みであり、API経由の有償・独占モデルの開発に注力してきた近年の戦略からの大きな転換を示しています。
この発表は単なる技術的な動きにとどまらず、競争環境、地政学的背景、そしてAIエコシステムの未来にまで影響を与える、戦略的な布石といえるでしょう。
1. 戦略的背景:緻密に計算された一手
まず、「オープンウェイト」と真の「オープンソース」の違いを明確にする必要があります。gpt-ossにおいて、OpenAIはモデルの「重み(weights)」をApache 2.0ライセンスの下で公開しました。これは最も柔軟性の高いオープンソースライセンスの一つであり、開発者、企業、研究者が自由にダウンロード・検証・自社インフラ上での実行、そして何よりも特定のタスクに向けたファインチューニングを行うことが可能となります。
しかし、訓練に使用されたデータセットや詳細なトレーニングコードなどの中核的な構成要素は非公開のままです。これは、OpenAIが広範な開発者コミュニティを惹きつける一方で、知的財産と中核的な競争優位を守るという、戦略的なバランスの上に成り立っています。
この決定の背景には多角的な動機が存在します。競争の観点から見ると、OpenAIは現在、強力なオープンソース系モデルの台頭に直面しています。特に中国のAlibabaのQwen、Zhipu AIのGLM、DeepSeek、そしてMetaのLlamaシリーズなどがその代表格です。高性能なオープンウェイトモデルを公開することで、OpenAIは再び影響力を取り戻そうとしています。
また、地政学的観点では、OpenAIおよびパートナーのMicrosoftは、今回の動きを「民主的AI基盤(democratic AI rails)」の構築と位置付けています。強力でオープンかつ米国的価値観に基づくツールを提供することで、「専制的AI(autocratic AI)」モデルに対抗するエコシステムを形成し、グローバルなAI競争におけるソフトパワーの源泉とする狙いがあります。
gpt-ossの登場は、従来のAPIベースの独占的ビジネスモデルを放棄するものではなく、むしろ「二層戦略」の構築を意味します。オープンウェイトモデルは、大規模な開発者や企業を惹きつける「ファネル(漏斗)」の役割を果たします。このようにしてOpenAIは、コミュニティのシェアを獲得し、ツールの標準(たとえば後述するHarmony形式など)を確立し、より高性能な独自モデル(o3、o4、GPT-5など)へのシームレスなアップグレードパスを提供するのです。これは、「AIの民主化」という顔を持ちながらも、非常に巧妙に設計されたロックイン戦略でもあります。
2. 技術アーキテクチャの概要:最優先されるのは効率性
| Model | Layers | Total Params | Active Params Per Token | Total Experts | Active Experts Per Token | Context Length |
| gpt-oss-120b | 36 | 117B | 5.1B | 128 | 4 | 128K |
| gpt-oss-20b | 24 | 21B | 3.6B | 32 | 4 | 128K |
技術的な観点から見ると、gpt-ossは「効率性を最優先する」という設計哲学に基づいて開発されています。今回公開された2つのモデルは、異なるハードウェア環境を想定して設計されています。gpt-oss-120bは総パラメータ数1170億で、データセンターや高性能サーバー向けに設計されており、gpt-oss-20bは総パラメータ数210億で、個人用PCやエッジデバイス向けに最適化されています。
最も注目すべきアーキテクチャ上の特徴は、Mixture-of-Experts(MoE)の採用です。これは、入力された各トークンに対してニューラルネットワーク全体をアクティブにするのではなく、関連する一部の「エキスパート(experts)」のみを選択的に動作させる手法です。具体的には、gpt-oss-120bでは1トークンあたり有効化されるパラメータは51億、gpt-oss-20bでは3.6億に抑えられており、推論時の計算コストとハードウェア要件を大幅に削減しています。
さらに効率化を図るために、OpenAIはMoE層に対して4ビット量子化手法「MXFP4」を採用しました。これは、NVIDIAの最新世代GPU(HopperやBlackwell)と互換性のある高効率な重み圧縮フォーマットです。MoEとMXFP4の組み合わせにより、gpt-oss-120bはNVIDIA H100のような80GBメモリ搭載GPU上で単独動作が可能となり、gpt-oss-20bに至っては16GBのVRAMしかないデバイス、つまり一般的なラップトップ上でも実行可能です。
このほかにも、gpt-ossモデルは128,000トークンという非常に広いコンテキストウィンドウを持ち、長文ドキュメントや複雑な会話の処理に対応しています。また、attention sinksやスパース・デンスattentionのハイブリッド構造などの革新的なattention機構が組み込まれており、高効率な情報処理を実現しています。さらに、GPT-4oと同じトークナイザーを共有しており、高い互換性とトークン化性能も確保されています。
3. ベンチマークによる性能評価
gpt-ossの性能は最も注目されている点の一つであり、その実力を示すためにOpenAIは印象的なベンチマーク結果を公開しました。
社内比較:「独自モデル」とほぼ同等の性能
OpenAIの主張によると、gpt-oss-120bは同社の有償独自モデルであるo4-miniと「ほぼ同等(near-parity)」の性能を実現しており、gpt-oss-20bもo3-miniと同等の推論ベンチマーク結果を示しています。これは非常に大胆な声明ですが、特定領域における数値データに基づくと、その主張には十分な根拠があります。
専門領域への特化:「推論」に焦点を絞る
ベンチマーク結果からは、gpt-ossが単なる汎用モデルの縮小版ではないことが読み取れます。これらのモデルは意図的に「推論」タスクに特化する形で設計・最適化されており、OpenAIのoシリーズモデルで採用されてきた人間のフィードバックに基づく強化学習(RLHF)の技術が引き継がれています。特定領域での卓越した性能は、トップモデルから選択的に知識を移転した結果であり、gpt-ossを汎用的なLLMではなく、専用ツールとして位置づけています。
- 数学分野:
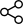
両モデルとも、AIME 2024および2025などの難易度の高い数学ベンチマークにおいて非常に高いスコアを記録しています。特に注目すべきは、gpt-oss-120bがAIME 2024で96.6%、gpt-oss-20bが96.0%という優れた結果を達成している点です。これは、0,000トークンを超える長い推論チェーン(Chain-of-Thought: CoT)を生成できる能力によるものであり、複雑な数学的推論を高精度で処理する力を示しています。
- プログラミング分野:
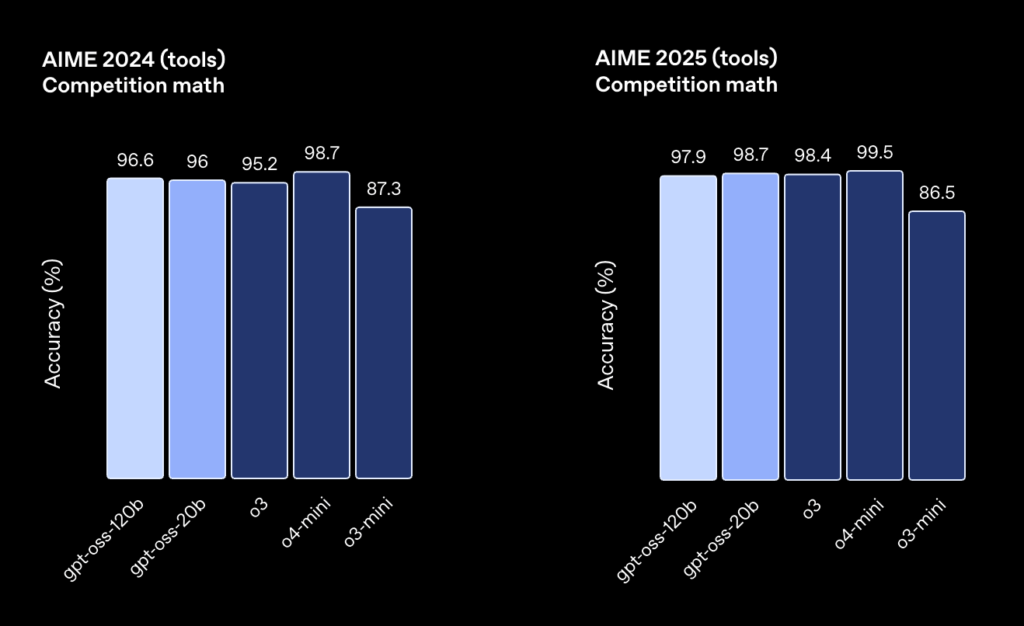
プログラミング能力においても、gpt-oss-120bは高い実力を示しています。CodeforcesスケールにおけるEloレーティングは2622で、これは有償モデルo4-mini(2719)に非常に近い数値です。また、ソフトウェアエンジニアリング分野のベンチマークであるSWE-Bench Verifiedにおいても、gpt-oss-120bは競争力のあるパフォーマンスを発揮しており、実用レベルでの応用が期待されています。
- 医療分野:
最も意外性のある結果の一つは、HealthBenchにおけるパフォーマンスです。gpt-oss-120bは、OpenAIの有償モデルであるGPT-4oを上回る性能を示しただけでなく、o3とほぼ同等の水準に達しています。
さらに注目すべきは、推論努力の調整(Adjustable Reasoning Effort)というユニークな機能です。開発者は、system messageを通じて推論の深さをlow、medium、highの3段階で指定することが可能です。これにより、応答速度、計算コスト、回答品質の間で柔軟なトレードオフが可能となり、現実世界での運用において非常に重要な機能となっています。
gpt-ossとOpenAIの独自モデルとの詳細な性能比較の表
定量的な視点を提供するために、以下の表では主要なベンチマークスコアをまとめ、gpt-ossモデルとOpenAIの独自モデルを直接比較しています。
| Benchmark | gpt-oss-120b | gpt-oss-20b | o4-mini | o3-mini | o3 |
| MMLU (General Knowledge) | 90.0% | 85.3% | 93.0% | 81.1% | 93.4% |
| GPQA Diamond (Reasoning) | 80.1% | 71.5% | 81.4% | 77.0% | 83.3% |
| Humanity’s Last Exam (HLE) | 19.0% | 17.3% | 17.7% | – | 24.9% |
| AIME 2024 (Math, with tools) | 96.6% | 96.0% | 98.7% | 87.3% | 95.2% |
| Codeforces (Coding, Elo) | 2622 | 2516 | 2719 | – | 2891 |
| SWE-Bench Verified (Coding) | 60.0% | – | 69.0% | – | 68.0% |
| TauBench Retail (Tool Use) | 67.8% | – | 67.8% | – | – |
出典:https://openai.com/index/introducing-gpt-oss/
4. 直接対決:gpt-oss vs 中国発の先進モデル群
gpt-ossはOpenAIの社内モデルとの比較において優れた性能を発揮していますが、本当の戦場はオープンソース領域にあります。ここでは、中国から登場した強力なライバル――Qwen(Alibaba)、GLM(Zhipu AI)、DeepSeekなどが、すでに非常に高い技術的基準を打ち立てています。

書類上の戦い:ベンチマークによる比較
ベンチマーク上で比較すると、gpt-oss-120bは競争力のある性能を示してはいるものの、必ずしも圧倒的というわけではありません。例えば、GPQA Diamondのスコアでは、gpt-oss-120b(80.1%)はDeepSeek-R1(81.0%)やQwen3(81.1%)にわずかに劣っています。一方で、AIME 2024のような数学ベンチマークでは、gpt-oss-120bがより優れた結果を示しています。
ここで重要なのは、テスト条件の一貫性が欠けているという点です。OpenAIによるgpt-ossの多くのベンチマークは、コードインタープリターやウェブ検索などのツールを有効化した状態で実施されていますが、競合他社のモデルは通常、**ツール無し(純粋なモデル性能)**でのスコアが報告されています。この違いにより、直接的な比較(いわゆる“リンゴ対リンゴ”)が困難となり、評価にバイアスが生じる可能性があります。
現実の厳しさ:コミュニティからのフィードバック
Redditなどの開発者コミュニティにおける報告や議論を分析すると、より複雑な現実が浮かび上がってきます。多くのユーザーが、gpt-ossの現実的なタスクにおける性能に「失望した」と語っており、華やかなベンチマークスコアとは対照的な評価を下しています。
- プログラミングと創造的な執筆:
実際のアプリ開発や創造的ライティングにおいて、Zhipu AIのGLM-4.5 Airは、gpt-oss-120bよりも優れているとの報告が多く見られます。
gpt-ossは、コードが短すぎる、推論に労力が見られない、または問題を不必要に複雑化するといった指摘がされています。 - 幻覚率(Hallucination):
初期レポートでは、gpt-ossが現実の事象や事実に関する質問に対して誤情報を生成しやすい傾向があると報告されています。
このように、ベンチマークスコアと実際の使用感に大きなギャップがあることから、gpt-ossは学術的なテストに過度に最適化された(いわゆる“ベンチマクシング”)可能性が指摘されています。一方、GLM-4.5のような中国製モデルは、理論性能をより実用的な形で変換できている印象が強く、実践的な使用において安定したパフォーマンスを発揮しているようです。
この対決は、異なる設計哲学の衝突でもあります。OpenAIは、117Bという巨大モデルでありながら、実際に使用されるパラメータを極端に削減(5.1B)し、量子化によって計算資源を節約する「軽量高速型」の推論最適化を重視。一方で、中国の研究機関は、トークンごとのアクティブパラメータ数を増やす(例:GLM-4.5 Airで12B)ことで、より豊かな出力を重視しているように見受けられます。
これは、推論速度 vs 出力品質というトレードオフの一例であり、開発者が自らのユースケースに応じて慎重にモデルを選定する必要があることを意味しています。
出典:https://www.reddit.com/r/LocalLLaMA/comments/1mifzqz/gptoss120b_vs_glm_45_air/
5. 独立した運用:自律性とセキュリティの両立
Open-weightモデル最大の利点の一つは、オンプレミス(自社環境)での完全な運用が可能であり、データ制御とセキュリティを完全に担保できる点にあります。
要件:「ホームグラウンド」での運用に必要なもの
gpt-ossモデルをローカルで実行するには、適切なハードウェアと実行環境が求められます。
- gpt-oss-120b:
少なくとも80GBのVRAMを搭載したエンタープライズ向けGPUが必要(例:NVIDIA H100、A100など)。 - gpt-oss-20b:
より柔軟で、最新のノートPCや個人向けワークステーション(GPUの場合は16GB以上のVRAM、CPUの場合は16GB以上のRAM)でも実行可能。
現在、コミュニティからのサポートも非常に充実しており、Ollama、vLLM、llama.cpp、Hugging Faceのtransformersなどの主要なフレームワークは、両モデルに完全対応。簡単なコマンドでローカルデプロイが可能です。
カスタマイズとファインチューニング:自分だけのモデルを作る
Apache 2.0ライセンスの下、gpt-ossモデルは自由に改変・再学習が可能です。これにより、特定分野(医療・法律・金融など)に特化した高精度な専用モデルを構築できます。
推奨されているファインチューニング手法は、LoRA(Low-Rank Adaptation)。
これは、膨大なパラメータ全体ではなく、少数の“アダプタ行列”のみを学習対象とすることで、計算資源とメモリを大幅に節約しつつ、非常に高い精度を実現できます。
特に企業ユースにおいては、自社内での処理=完全なセキュリティ確保という大きなメリットがあります。
クラウドAPIを通さず、機密データを外部に送信する必要がないため、情報漏洩リスクを排除できます。
「OpenAI Harmony」:避けられない新たな前提条件
gpt-ossには、**OpenAI独自かつ必須のプロンプトテンプレート「OpenAI Harmony」**が組み込まれています。これを使用しなければ、モデルが正常に応答しません。
Harmonyは単なる技術仕様ではなく、**OpenAIの戦略的“堀”**としても機能しています。独特で複雑なプロンプト構造を強制することで、他のオープンソースモデルへの移行を難しくしつつ、自社APIへのスムーズなアップグレードを促しています。
Harmonyの主な特徴は以下の通り:
- 特殊トークン: <|start|>、<|end|>、<|channel|>など、チャット構造を明示。
- 拡張ロール: userとassistantに加え、developer(ツール指示用)とsystem(システム設定用)を導入。
- 出力チャネル: analysis(推論プロセス)、commentary(ツール呼び出し)、final(最終応答)という3系統の出力を区別可能。
開発者向けに、OpenAIはPythonとRust用の**公式ライブラリ「openai-harmony」**も公開しています。
自由と責任:Open-Weightの本質
gpt-ossモデルのリリースは、セキュリティの利点と引き換えに、責任の所在をユーザー側に完全移譲することを意味します。
OpenAIは事前に厳格な安全性評価を行っているとしつつも、一度リリースされたモデルは“回収不能”であり、OpenAI側から追加的なリスク軽減策を講じることは不可能としています。
したがって、企業がこのモデルを業務に活用する場合、独自のフィルタリングシステム、ファイアウォール、セキュリティ対策の整備が必須となります。
6. 支援エコシステム:大手プラットフォームが参入
gpt-ossの登場は単独で行われたわけではありません。それは強力なテクノロジー企業によるエコシステムの支援を受けており、AI業界の成熟を示すとともに、広範な導入を可能にしています。
- Amazon Web Services (AWS): 大きな驚きをもって、AWSはgpt-ossがAmazon BedrockおよびSageMaker JumpStartに初めて登場するOpenAIのモデルであると発表しました。これは技術業界において地政学的にも重要な意味を持ちます。Apache 2.0ライセンスによって、OpenAIはMicrosoftとの独占契約を回避し、最大のライバルであるAWSと協業する道を開いたのです。この動きは双方に利益をもたらします。OpenAIは数百万のAWSユーザーへの影響力を大幅に拡大でき、AWSはAI製品ラインアップの空白を埋め、Azureとの競争力を強化できます。
- Microsoft: 戦略的パートナーとして、Microsoftはgpt-ossをAzure AI FoundryおよびWindows AI Foundryに統合しました。これにより、クラウド上での実験からエッジデバイスへの展開まで、一貫したAI開発の流れが実現されます。
- NVIDIA: AIにおける中核的なハードウェア基盤として、NVIDIAはgpt-ossモデルをCUDAエコシステム、TensorRT-LLMライブラリ、最新GPU(例:Blackwell)向けに最適化。たとえば、GB200 NVL72システムで1.5百万トークン/秒の推論速度が可能になるなど、驚異的な性能を実現しています。
- その他のプラットフォーム:
- Databricksはgpt-ossをいち早く統合し、企業向けにデータガバナンス、監視、ファインチューニングツールを提供。
- Hugging Faceは引き続きコミュニティの中心として、モデルのホスティング、ディスカッション、共有の場を担っています。
このように、ハードウェア(NVIDIA)、クラウド(AWS、Azure)、データ基盤(Databricks)といった全方位のエコシステムに同時かつ連携して登場したことは、もはや新しいAIモデルのリリースが単独ではなく、「フルスタックAIファクトリー」に直接組み込まれる時代を示しています。こうした統合により、MLOps、ガバナンス、セキュリティとの連携が即座に実現され、大企業による導入ハードルを大幅に下げることができます。
7. 結論:gpt-oss に未来はあるか?
gpt-oss-120bおよびgpt-oss-20bのリリースは、2025年のAI業界における最も重要な出来事の一つです。これは、OpenAIがオープンソースの舞台に再び本格参入したことを意味し、世界的なAI競争を再構築しうる戦略的な賭けでもあります。
要約と評価
- 強み:
- 推論性能: 数学や競技プログラミングなど、推論タスクにおいて非常に高いパラメータ単位の性能を発揮。
- 効率的なアーキテクチャ: MoE構造とMXFP4量子化の組み合わせにより、比較的低スペックのハードウェアでも動作可能で、コスト削減につながる。
- 柔軟なライセンス: Apache 2.0ライセンスにより、商用利用・修正・再配布が自由。
- データ主権とセキュリティ: 自社環境でのホスティングにより、機密データの完全なコントロールが可能。
- 強固なエコシステム: AWS、Microsoft、NVIDIAなどの大手企業による初期段階からの支援。
- 課題と注意点:
- 実運用とのギャップ: ベンチマーク上の性能と、実際のタスク(特にコーディングや創造的作業)との間に差がある可能性。
- 幻覚リスク: 初期レポートでは、他の主要な専用モデルに比べて幻覚(誤情報)の頻度がやや高い可能性が指摘されている。
- Harmonyフォーマットの壁: 入力形式にHarmonyを必須とする仕様は、学習コストがかかり、他のモデルへの切り替えを難しくする恐れがある。
- セキュリティ負担の移行: セキュリティ対策や悪用防止の責任はすべてユーザー側に委ねられる。
gpt-oss の活用が適しているのは?
以下のような企業や開発者に特に向いています:
- オンプレミスやプライベートクラウド上での強力な推論性能が求められる企業・開発者。
- データ主権やセキュリティ要件が厳格な、金融・医療・行政機関。
- MoEアーキテクチャや新しいファインチューニング技術、論理的な推論プロセスの研究に興味を持つ研究者。
- OpenAI APIを既に活用しており、セキュリティ強化やコスト削減のために自社ホスティングへ移行を検討している企業。
影響と今後の展望
gpt-ossは、既存の専用モデルを打倒する「革命」ではなく、OpenAIによる戦略的な「再配置」です。有料APIモデルの代替ではなく、より広いエコシステムを構築するための補完的存在と位置づけられます。この動きはオープンソース分野における競争をさらに加速させ、他社にも継続的な技術革新と実用性の証明を求めることになるでしょう。
開発者にとって、gpt-ossは魅力的でありながらも挑戦を伴う選択肢です。高い推論力とデータ制御の自由を提供する一方で、Harmonyフォーマットの学習コスト、セキュリティ管理の責任、そして期待通りに動作しないリスクも含まれます。
テクノロジーリーダーや開発者にとっての最も重要なアドバイスは次の通りです:
「信じるべきだが、必ず検証せよ」(Trust, but verify)
ベンチマークの数値はあくまで出発点であり、自社のタスクやデータセットに基づいた綿密な検証こそが、実運用における成功を左右する鍵となります。