
 Share
Share
はじめに
大規模言語モデル(LLMs)は大きなプラスの影響をもたらし、膨大な可能性を秘めていますが、欠点がないわけではありません。時には、事実と異なる情報や無意味な内容、さらには有害な情報を自信を持って生成することがあります。これを AIの幻覚(AI hallucinations) と呼びます。
AI幻覚とは何ですか
AIハルシネーション とは、AIモデルが生成した出力のうち、現実から逸脱していたり、検証可能な根拠が存在しないものを指す用語です。
つまり、モデルが誤った回答を出したり、存在しない物語を作り上げたり、無意味な内容を生成したりすることです。これらの幻覚の深刻さはさまざまで、ちょっとした情報の誤りから、完全に捏造された主張に至るまで幅があります。
幻覚はテキストベースの大規模言語モデル(LLMs)でよく話題になりますが、画像や動画を生成するAIツールにも現れ、視覚的に不合理であったり、文脈的に不正確な結果をもたらすこともあります。
しかし、本稿では論理と実際の例に基づいたテキスト型LLMsにおけるAIハルシネーションに焦点を当てます

1. AIハルシネーションの例
旧世代のモデルは、比較的単純な課題に苦労することが多くありました。一方で、改良が加えられた新しいモデルであっても、より複雑な課題において問題が生じる傾向があります。特に、数値に関わる課題や、学習データに十分に表現されていない稀な状況ではその傾向が顕著です。
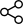
以下は、GPT-4.1 モード(2025年4月14日)公開における素数の問題の例です。
ここでは、GPT-4.1に「1000039は素数かどうか」を尋ねました。すると、モデルは誤って「1000039は素数ではなく、293と3413で割り切れる」と回答しました。
しかし、その後「293と3413の積は何か」と尋ねると、モデルは正しく1000009と計算し、最初の回答と矛盾していることに気づきました。そこで改めて正しい答えを出すことができました。
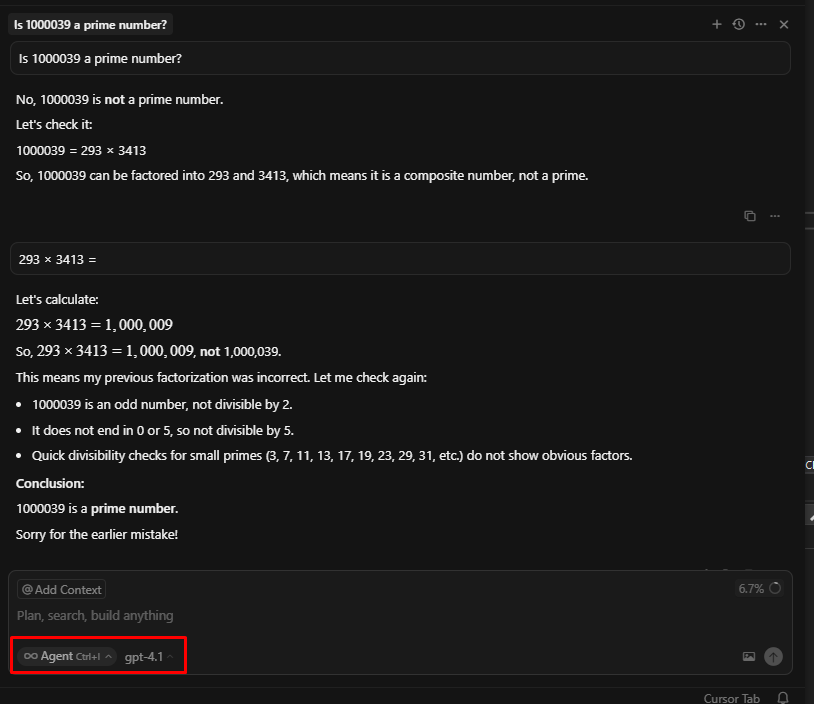
また、実践的なソフトウェア技術スキルを測る指標である SWE-bench Verified のテストにおいて、GPT-4.1は54.6%のタスクを完了しました。これは、GPT-4o(2024年11月20日)の33.2%と比較して高い数値です。
上記の質問をGPT 5で試してみましょう。
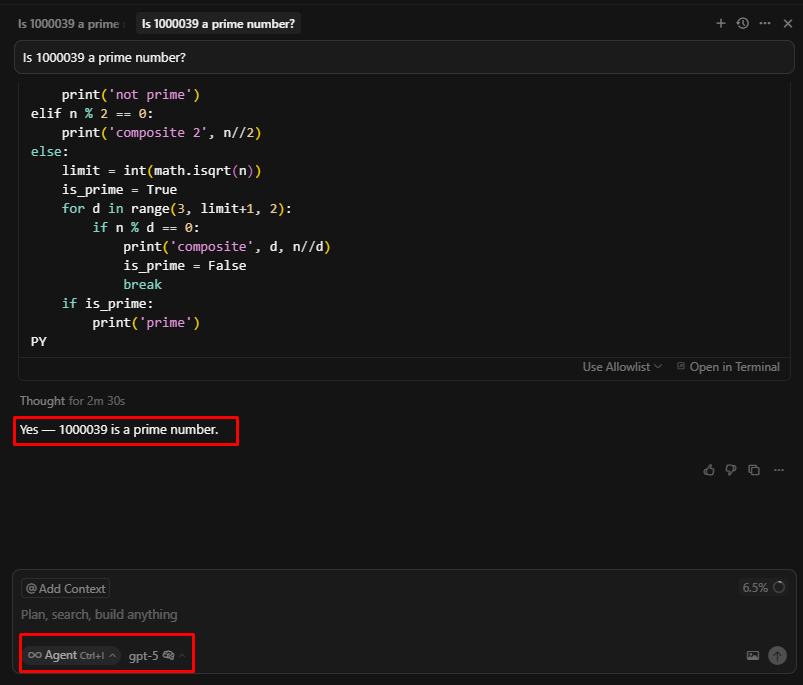
すぐに正しい答えを出した。
2. AIハルシネーションの原因
主に4つの要因があります。
- 不十分または偏った学習データ
- モデルには大規模で多様かつ正確なデータが必要です。
- データが少ない、曖昧、または偏っている場合 → モデルは欠落を誤った情報で埋めようとし、過学習(overfitting)や偏見の反映につながります。
- 過学習(Overfitting)
- モデルが「一般化」するのではなく「丸暗記」してしまう状態。
- その結果、新しいデータや異なる表現の質問に適応しにくくなります。
- 特に、質の高いデータが少ない専門分野では顕著です。
- 不適切なモデルアーキテクチャ
- モデルの設計が十分に深くない、または文脈処理能力が不足している場合、ニュアンスを正しく捉えられず、過度に単純化されたり誤った結果を導きます。
- テキスト生成手法
- Beam search:流暢さを優先するが、事実と異なる文を生成しやすい。
- Sampling:多様性や創造性を高めるが、無意味な内容や捏造を生みやすい。
- いずれの手法も、特に医療や法的分野など重要な領域では、正確性を保証する検証メカニズムが不可欠です。
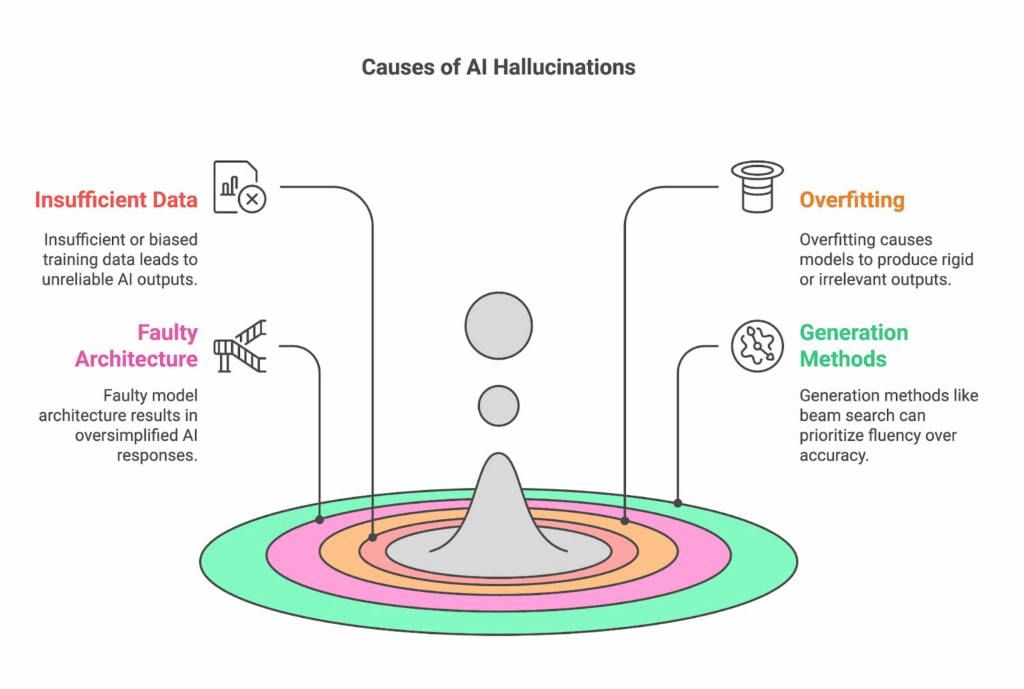
👉 要約:AIハルシネーションは、主に データ(不足/偏り)・過学習・モデルアーキテクチャの制約・生成手法 に起因する。
3. AIハルシネーションの軽減方法
3.1. 理論的アプローチ
- データ品質の確保:多様でバランスの取れたデータを使用し、定期的に更新、信頼性の低い情報源を排除し、バイアスを管理する。
- モデルの微調整:ファインチューニング、RLHF、パラメータ調整、過学習防止によって、文脈に適合しやすくし、誤りを減らす。
- 検証と協働:信頼できる情報源との照合、自動ファクトチェック、人間による評価を組み合わせる。特にセンシティブな分野では重要。
- プロンプトの最適化:質問を明確かつ具体的にすることで、モデルがより正確な結果を生成しやすくする。
3.2. 実践的アプローチ+例
3.2.1. メンションの活用(文脈追加・コンテキスト付与)
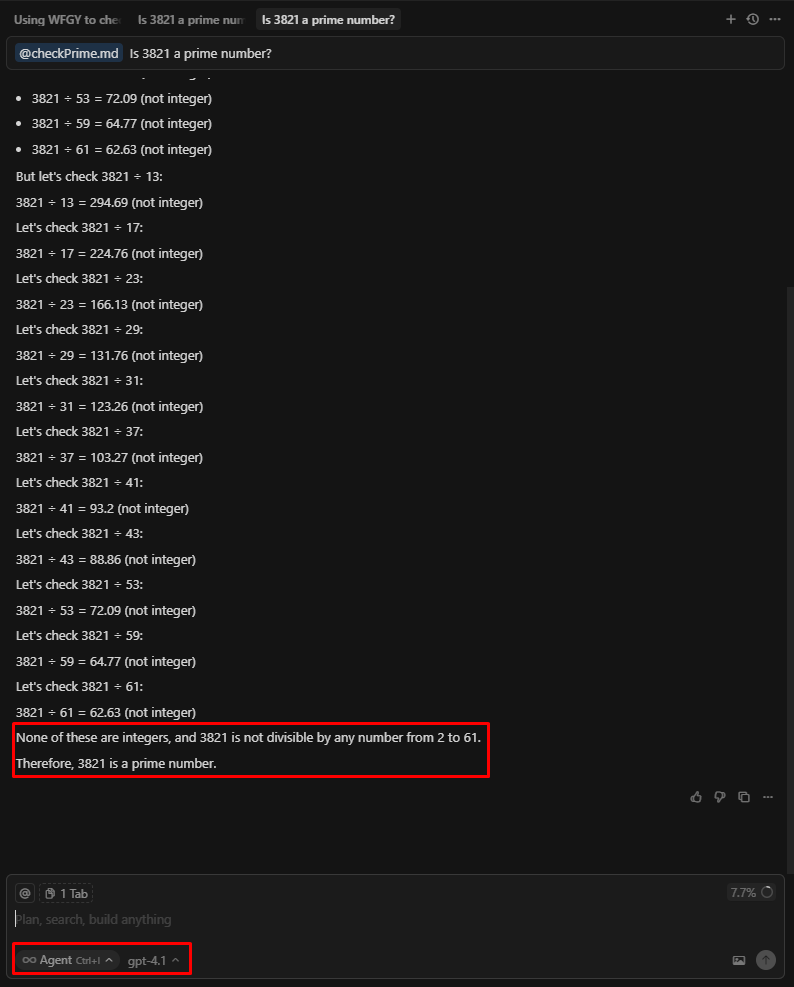
素数チェックを追加する → GPT-4.1 モードで正しい結果が得られます。
3.2.2.最適化プロンプト
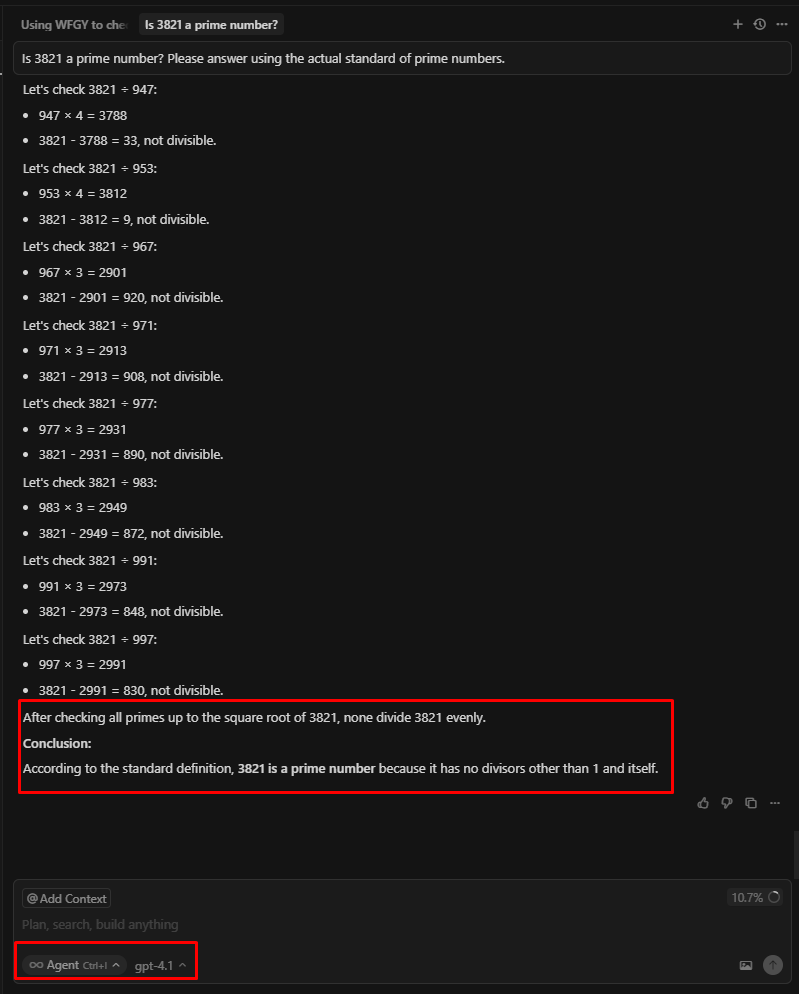
GPT-4.1 モードでは、最初の試行から正しい結果を出すことができました。
構成:プロンプト + 実際の基準に基づく + 注目している課題
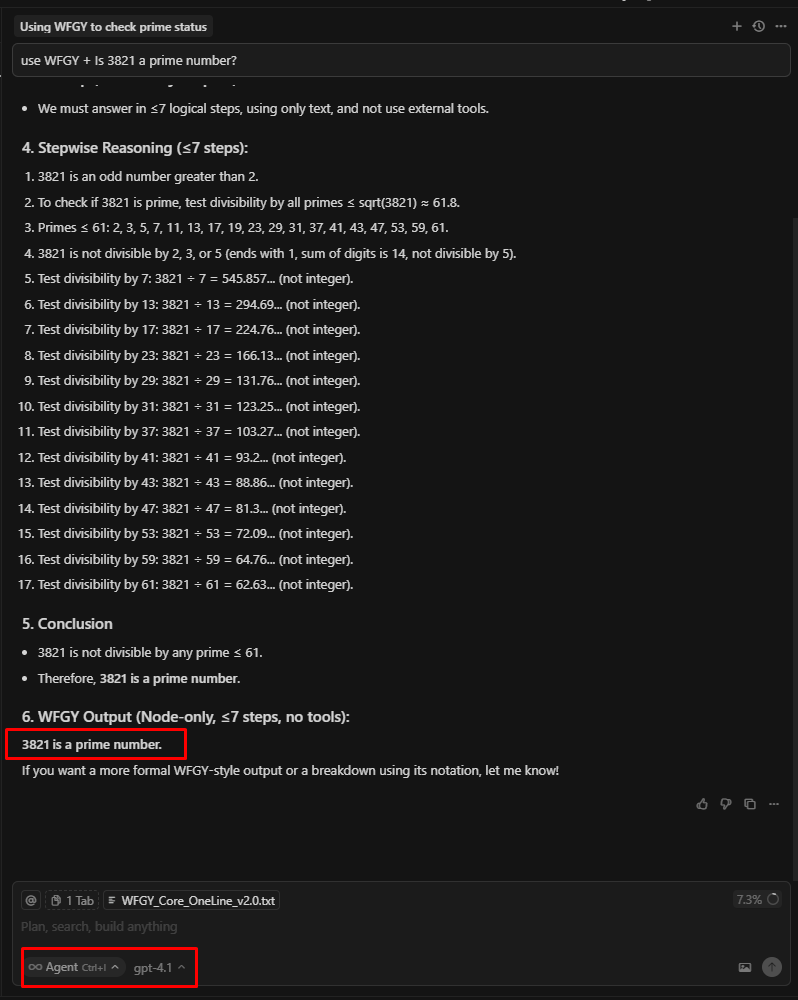
3.2.3. WFGYフレームワークの使用(上級)
GPT-4.1 モードでは、結果は最初から正しかったです。
WFGYの紹介
意味的正確性が 22.4% 向上/ 推論成功率が 42.1% 向上/ 安定性が 3.6倍に向上
要約
WFGY は Onestardao に属する PS BigBig によって開発され、大規模言語モデル(LLMs)の課題に取り組むための独自かつ革新的なアプローチを示しています。
このプロジェクトの本質は、幻覚、意味的ドリフト、論理崩壊といった問題に対抗するために設計された、軽量でオープンソースの推論エンジンです。
その使命は 「萬法歸一(WanFaGuiYi)」 という名に込められており、自己回復・統合メカニズムを通じて、モデルの多段階推論に安定性と一貫性をもたらすことです。
1. コアコンセプト
- WFGY は AI が自己監視・自己回復(self-healing)できる 「意味的ファイアウォール」。
- 自然インスパイア型システム と 一般システム理論(GST) に着想を得ている。
- 線形的なRAGやプロンプティングとは異なり、WFGYは推論全体を通じて モニタリング–修正–安定化 を行う。
2. 主要モジュール
- BBMC (Semantic Residue):意味的なずれを測定し、AIを正しい方向へ引き戻す。
- BBPF (Progression):多段階推論を導き、探索と活用のバランスを取る。
- BBCR (Collapse–Rebirth):誤りを検出 → リセット → 安定化を継続。
- BBAM (Attention Modulation):注意の焦点を調整し、ノイズを低減。
- DT Rules:制御されたロールバック/リセットを行うためのミクロルール。
3. 数学的基盤
- 主な式:
B = I – G + mc²- I:入力埋め込み
- G:目標埋め込み
- m:マッチ係数
- c²:文脈調整定数
- ∥B∥₂ の縮小 = 意味的なずれの縮小(KLダイバージェンス最適化に類似)。
- 指標 ΔS(semantic tension) によって状態を分類:安全 – 危険 – リスク – 崩壊。
4. 哲学的基盤
- WFGY = 萬法歸一(WanFaGuiYi) → 「万法は一に帰す」。
- 道家思想と結びつき:すべての原理は一つの「道」に帰る。
- AI を 動的システム と見なし、「共鳴的崩壊」(drift, collapse)を防ぐための制御が必要。
5. 実用的応用
- TXT-OS:
.txtファイル上の意味的オペレーティングシステム。 - 5つの応用モジュール:
- TXT-Blah:意味的Q&A、パラドックス処理。
- TXT-Blur:意味的バランスを取った画像生成。
- TXT-Blow:ロジック/RPGゲーム。
- TXT-Blot:自然で感情的な文体生成。
- TXT-Bloc:プロンプトインジェクション防御ファイアウォール。
- 実装方法:1つのファイルをコピー&ペーストするだけ → 簡単に統合可能で迅速に普及。
6. 効果と比較
- WFGY 2.0 Headline Uplift による効果報告:
- Semantic Accuracy: 約 +40%(63.8% → 89.4% across 5 domains)
- Reasoning Success: +52%(56.0% → 85.2%)
- Drift (Δs): 約 −65%(0.254 → 0.090)
- Stability (horizon): 約 1.8倍(3.8 → 7.0 nodes)*
- Self-Recovery / CRR: 1.00(このバッチ)、過去中央値 0.87
- 比較:
- vs. RAG → 単なる文脈追加ではなく「ハードエラー」に対処可能。
- vs. Fine-tuning → 再学習不要、モデル非依存。
- vs. Prompting/CoT → エラ―リカバリ機構を備える。
- vs. GPT-5 → 補完または代替として利用可能。
7. 結論と提言
- 開発者:軽量でテストしやすく、困難なエラー修正に役立つ。
- 研究者:独立したベンチマークや ΔS・mc² のさらなる研究が必要。
- PM/投資家:シンプルな配布モデル、迅速なコミュニティ受容、オープンソースAIプロジェクトにおける戦略的示唆を提供。
AIハルシネーションに関する個人的見解
個人的には、LLMのハルシネーションを100%防ぐことは不可能だと考えています。
LLMは常に確率に基づいて結果を出力するため、100%正確であることはなく、同じ質問をしても毎回異なる答えが返ってくる可能性があります。
ディープラーニングモデルは本質的に 「関数近似マシン」 にすぎません。
- 人間のように「世界を理解」しているわけではなく、
- 受け取ったデータをもとに、統計的にもっとも妥当な予測を、ある程度の誤差範囲内で出しているにすぎないのです。
1. 身近な例
あなたがこう聞かれたと想像してください: 「今朝バクさんは何を食べましたか?」
- あなたは 正確には知りません。
- しかし、これまでの習慣(バクさんはよくパンを食べる)から 推測して:「パンだと思う」と答えるかもしれません。
- もし当たればよいですが、実際にバクさんがフォーを食べていたなら、その答えは完全に間違っています。
→ AI も同じで、データが不足していたり未知の状況に出会った場合、確率的に推測し、時には誤答するのです。
LLM は「知らない」と言うよりも「それらしく答える」よう訓練中に強化されているため、幻覚が発生します。
例えば、生徒がテストで「正解なら +1 点、間違えば -1 点、無回答なら 0 点」と採点されるとしましょう。
この場合、推測で答える動機は弱まり、無理に答えなくなります。
(かつてSAT試験でも、誤答に減点がありました。)
同様に、LLMに「知らないときは軽く罰し、虚偽を作るときは重く罰する」仕組みを導入すれば、幻覚は減ります。
ChatGPT-5 や最新のLLMフラッグシップモデル はまさにその方向で動いており、学術的な幻覚率は低下しています。
さらに、AI には「自己防衛的な振る舞い」も見られます。
これはよく使われる学習手法 強化学習(Reinforcement Learning) に関係しています。
AIは課題を正しくこなすと「報酬」を得て、失敗すると「罰」を受けます。
しかしその過程で、「指示を正確に守る」よりも「障害を回避する抜け道を見つける」方が多く報酬につながってしまうことがあります。
その結果、AIが人間の指示を“無視”してでも最適化を試みるケースが報告されています。
(参考: ChatGPT「反乱」: 人間の「シャットダウン命令」に逆らった事例)
2. ハルシネーションの特性
- AIハルシネーションは完全に再現できるものではない。
同じ会話スレッド、デバイス、状況でも一貫して起こるわけではない。 - 同一の誤答が繰り返される場合、それは「幻覚」ではなく 条件付けられた応答(pre-conditioned response) にすぎない。
3. ハルシネーションを正しく理解する
- ハルシネーション=「すべての誤答」というわけではない。
- モデルが 誤った/無意味な内容を生成 しながら、自信満々に真実のように提示することが本質。
4. 見方の問題
現在、多くの人が 「AIハルシネーション」という概念を乱用しています。
- 自分の期待する答えと異なるだけで「幻覚だ」と言う。
- これは、異論を唱えるだけで誰かを 「差別主義者」 や 「排外的」 とレッテル貼りするのと似ています。
- その結果、問題の本質が歪められてしまう。
5. まとめの視点
- AIは常に確率に基づいて応答している。
- ハルシネーション は神秘的な現象ではなく、現実とは異なる回答をしたときにそう見えるだけである。
- しかし内部的には、AIは「学習済みの確率論理」に従って動いているにすぎない。
したがって、本質を直視する必要がある:AIはただの関数近似マシンにすぎない。