
 Share
Share
初めに
近年、人工知能(AI)や大規模言語モデル(LLM)の進歩により、人間のような自然な言語処理が可能なシステムの開発が進んでいます。
これらの進展により、AIは私たちの生活やビジネスに大きな影響を与えており、デジタル情報の活用が新しい次元に到達しています。このような背景の中で、検索拡張生成(RAG)などの技術が注目を集め、特定の情報検索とAIの生成能力を組み合わせた新たなソリューションが生まれています。
RAG(Retrieval-Augmented Generation)は、近年AI技術の中で注目されているキーワードの一つです。それはどのような仕組みで機能しているのでしょうか。
検索拡張生成とは何ですか
検索拡張生成 (RAG) は、大規模な言語モデルの出力を最適化するプロセスです。そのため、応答を生成する前に、トレーニングデータソース以外の信頼できる知識ベースを参照します。
大規模言語モデル (LLM) は、膨大な量のデータに基づいてトレーニングされ、何十億ものパラメーターを使用して、質問への回答、言語の翻訳、文章の完成などのタスクのためのオリジナルの出力を生成します。
RAG は、LLM の既に強力な機能を、モデルを再トレーニングすることなく、特定の分野や組織の内部ナレッジベースに拡張します。LLM のアウトプットを改善するための費用対効果の高いアプローチであるため、さまざまな状況で関連性、正確性、有用性を維持できます。

LLM は、自然言語処理(NLP)アプリケーションを支える重要な技術ですが、応答の予測不能性や古い情報を提供する問題があります。また、信頼性の低いソースから情報を生成したり、用語の混乱により不正確な応答を生じることも課題です。
RAG はこれらの課題を解決するアプローチの一つです。LLM が信頼できるナレッジソースから情報を取得するよう誘導し、生成される応答の正確性と制御性を向上させます。これにより、ユーザーはより信頼性の高いチャット体験を得ることができます。
検索拡張生成の仕組み
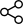
検索拡張生成(RAG)は、検索と生成を組み合わせた多段階プロセスです。その仕組みを以下に説明します。
① 検索(Retrieve)
質問を入力すると、外部ナレッジから質問に関連する内容をAIが検索します。
ベクトルデータベースから情報を検索し、質問と関連度の高い情報がLLMへ追加情報として与えるコンテキストとして抽出します。
② 拡張(Augment)
前段の検索(Retrieve)の段階で検索した情報を、ユーザーが入力した質問に追加します。(=拡張)
外部情報が追加されたコンテキストを、プロンプトテンプレートに入力します。
③ 生成(Generate)
最後に、拡張されたプロンプトがLLMに連携され、外部情報も加味した内容で回答が生成されます。
このプロセスにより、検索した補足情報を活用した、正確性が高く文脈に適した回答が提供されます。この仕組みは、特定の分野や専門領域における質問において特に有効です。
RAG(検索拡張生成)とファインチューニングの違い
生成AIがクローズドな情報を扱うための方法として、RAG以外には「ファインチューニング」が挙げられます。
RAGとファインチューニングの違いは「生成AIに学習させるかどうか」という点です。
ファインチューニングは、生成AIに新しい知識を覚えさせ、その扱える情報を増やす方法です。一方で、RAGは生成AIに新たな知識を学ばせるのではなく、必要なときに参照できるデータベースを整備する仕組みです。
人間に例えると、ファインチューニングは新しい知識を暗記させることに近く、RAGは必要な情報をいつでも引き出せるよう資料を整えておくことに似ています。
AWSを活用したサーバーレスRAGアーキテクチャ
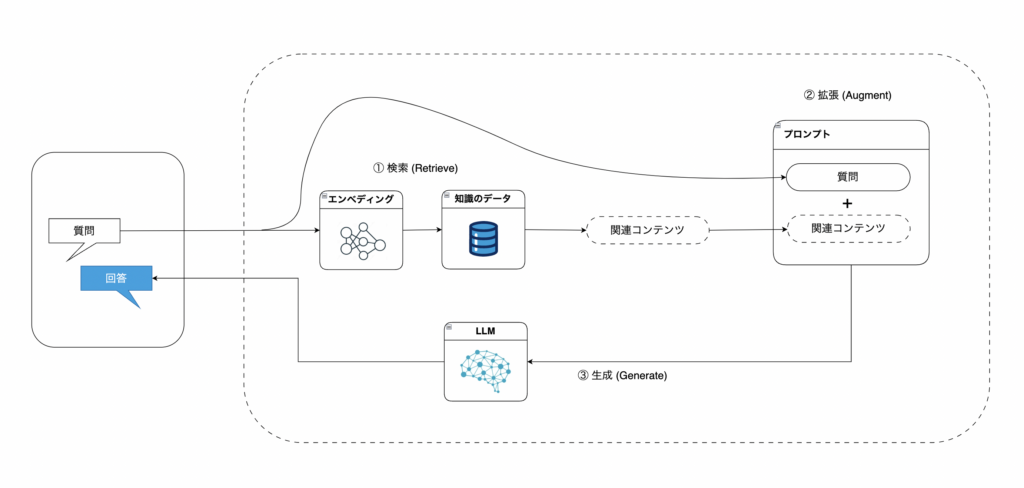
このアーキテクチャにおける主要なステップは以下の通りです。
①ユーザー入力 (プロンプト) の送信
ユーザーはAWS AmplifyでデプロイされたWebアプリケーションにプロンプトを送信します。このアプリケーションのソースコードはGitHubなどのリポジトリに保存されており、チャットインターフェースを通じてリクエストを送信可能です。
②埋め込みベクトルの生成
ユーザーのプロンプトはAWS Kendraに送られ、埋め込みモデルを使用してベクトル化されます。
③データストレージ層
データストレージ層には、ファイル、画像、動画、文書、CSVなどの非構造化データが格納されています。
④データのインデックス化と検索
S3に保存されたデータは、ユーザーが同期ジョブを実行するたびにKendraの埋め込みモデルでベクトル化されます。Kendraはこのベクトル化データとユーザーのプロンプトを使用してセマンティック検索を行い、関連性の高いデータや文書を「知識」として返します。
⑤応答生成
Lambda関数がLangChainオーケストレーターとして機能し、Kendraから取得した「知識」を使ってLLMモデル(例: Antropic Claude)に接続します。LLMは「知識」とプロンプトを組み合わせて応答を生成し、AWS Amplifyでホストされたチャットインターフェースに応答を返します。
⑥会話履歴の保存
生成された応答のコピーはDynamoDBに保存され、会話履歴として管理されます。これにより、フォローアップのプロンプトに対して文脈を考慮した応答を生成できます。
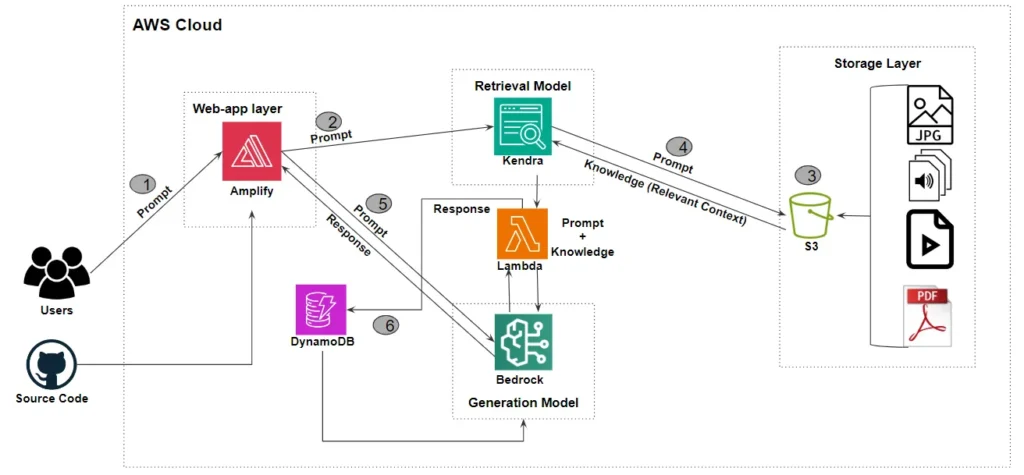
PIGPTの紹介

PIGPTは、提供されたPDFドキュメントを活用し、検索拡張生成(RAG)技術を用いてチャットボットを構築するサービスです。ユーザーはドキュメントをアップロードすることで、その内容を元に質問に正確かつ的確に回答するAIを作成できます。これにより、企業内での効率的な情報共有や、特定の知識に基づくカスタマイズされた顧客対応が可能になります。また、PIGPTはチャットの履歴を記憶し、それを活用して文脈に応じたより良い結果を提供できる点が大きな強みです。
たとえば、製品マニュアルや社内ガイドラインをPIGPTにアップロードすることで、ユーザーや従業員の質問にすぐに答えるインテリジェントなサポートツールとして活用できます。

詳細情報や利用方法については、公式ウェブサイトPIGPTをご覧ください。ぜひ試して、情報管理と顧客サポートの新しい可能性を体験してみてください!
結論
本記事をご覧いただき、誠にありがとうございます。
もし貴社が生成AIの統合や関連製品の開発についてご相談をお考えの場合は、ぜひ [email protected] までご連絡ください。できる限り早急にご返信させていただきます。