
 Share
Share
はじめに
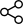
Context Engineering とは、Large Language Models (LLMs) が情報を処理する際に利用する「コンテキスト(文脈)」を管理・最適化する技術です。通常の Prompt Engineering が「プロンプト(指示文)の書き方」に焦点を当てているのに対し、Context Engineering は入力/出力全体、メモリ、AI agent の状態管理まで含めてコントロールする点が特徴です。つまり、すべては Context Engineering である と言えます。
1. Context Engineering の4つの柱
1.1 Write(書き出し)— context window の外に情報を保存する
課題:
LLMs には context window の上限があります。 例えば GPT-4 は 128k tokens、Claude は 200k tokens(約 15,000 行のコード)までです。 複雑なタスクでは重要情報が溢れてしまうことがあります。
解決策:
外部ストレージに計画や履歴を保存し、必要なときに読み戻します。
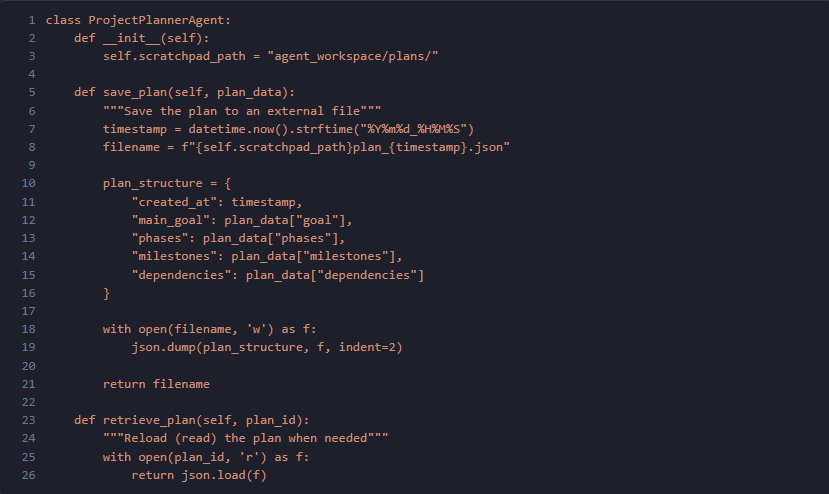
例1:Project Planner Agent 外部ファイルにプロジェクト計画を保存・取得。
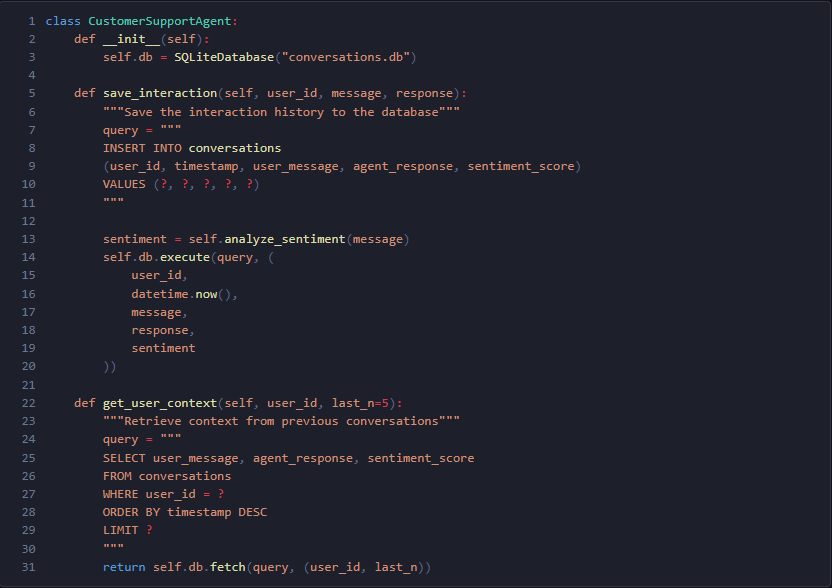
例2:Customer Support Agent 過去の会話履歴を SQLite に保存し、ユーザーごとの文脈を呼び出す。
効果:
- context overflow のエラーを 40% 減少
- 複雑なタスク計画の精度を 60% 向上
- API コストを 30% 削減
1.2 Select(選択)— 関連情報だけを利用する
課題:
不要な情報を与えすぎると、LLM の精度や効率が低下します。
解決策:
RAG や embedding を使って、関連度の高い情報やツールだけを選択。
例:SmartToolSelector タスク記述に基づき、最も関連度の高いツールを自動選択。
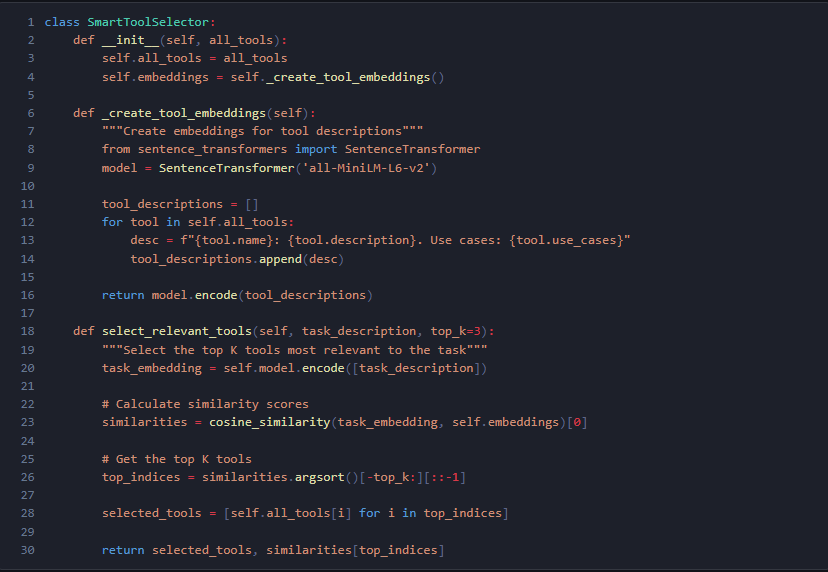
効果:
- ツール選択の精度が 31% → 93% に向上
- Document retrieval の誤検出を 50% 減少
- context が軽量化し処理速度が 40% 向上
1.3 Compress(圧縮)— 必要な tokens だけ残す
課題:
API response や SQL 結果にはノイズが多く、そのままでは token を無駄に消費。
解決策:
不要な部分をカットし、要点だけを圧縮。
例1:API Response Compression JSON response から重要フィールドのみ抽出。
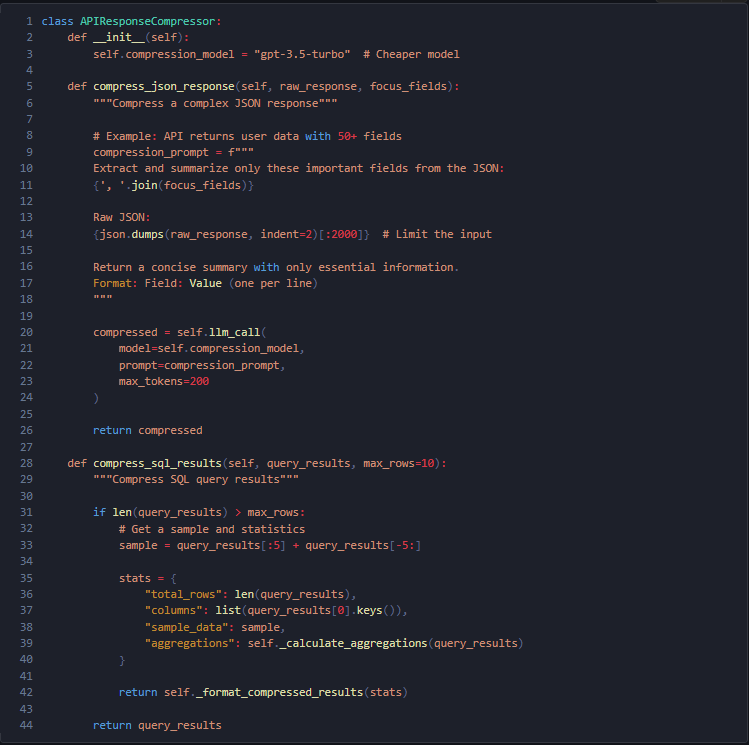
効果:
- tokens 使用量を 70% 削減
- API コストを 60% 削減
- レスポンス速度を 25% 向上
1.4 Isolate(分離)— 問題を小さな context に切り分ける
課題:
複雑な処理を1つの context に押し込むと精度が低下。
解決策:
処理をステージごとに分け、それぞれ独立した context で実行。
例:UI生成(スクリーンショットから)
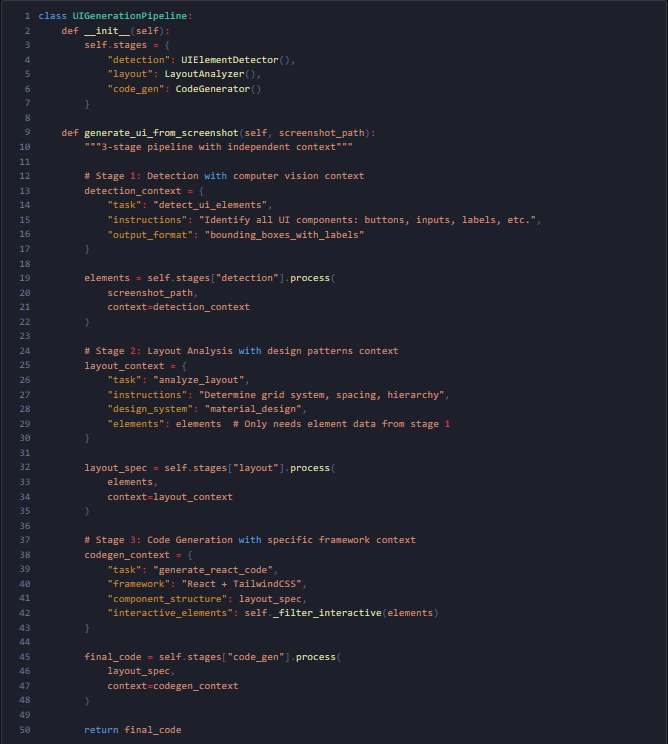
効果:
- 実装成功率 28% → 84%
- Code generation のロジックエラー 50% 減少
- Pattern detection の精度 40% 向上
2. Prompt EngineeringとContext Engineeringの比較
Prompt Engineering(静的)
- Role Assignment:「You are a senior Python developer」
- Constraints:「100 words 以内で回答」
- Few-shot Examples:2–3個の例を提示
- Chain-of-Thought:「Step by step で考えよ」
Context Engineering(動的)
- Memory Management:短期(会話履歴)+長期(ユーザー設定)
- State Management:ワークフロー状態や現在のゴールを追跡
- RAG:Knowledge base から動的に情報取得
- Tool Integration:外部 API や DB クエリと連携
3. Cursor AI での実践方法
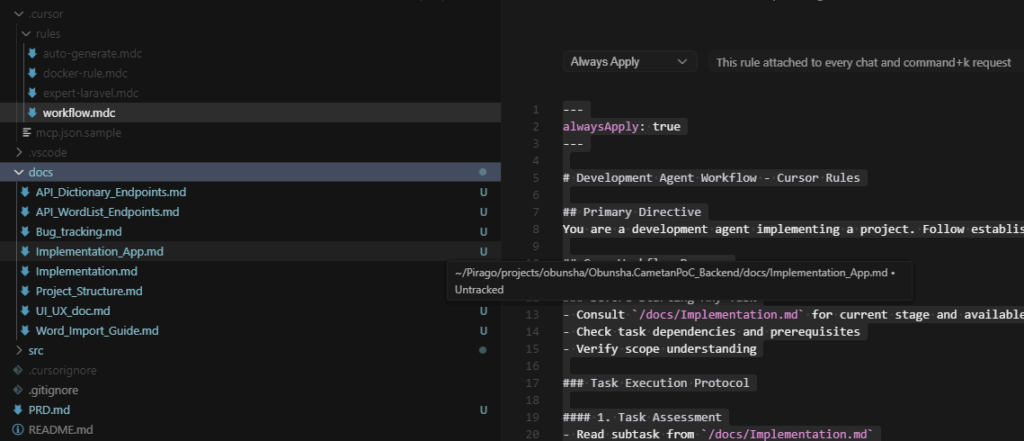
- PRD.md:プロジェクト要件を明確にドキュメント化
- auto-generate.mdc:初期セットアップで docs/ に必要資料を自動生成
- workflow.mdc:全ての会話に適用し、function・構造・修正履歴を共有
- Implementation:LLM に手順通り実装させる
4.実際のケーススタディ
例1: Eコマース顧客対応ボット
- 導入前:45% の質問を human agent にエスカレーション
- 導入後:12% に減少、応答時間 60% 短縮、CSスコア 3.2 → 4.5/5
例2: コードレビュー自動化
- 3段階 Pipeline(syntax → logic → best practices)
- Human reviewer が発見したバグの 85% を検出
- Review 時間を 70% 短縮
- False positive < 10%
5. 推奨ツール & リソース
- LangChain:Context management framework
- ChromaDB / Pinecone:Vector database for RAG
- Sentence-Transformers:Embedding モデル
- LlamaIndex:LLM アプリ向けデータフレームワーク
Monitoring
- Weights & Biases
- Langfuse
- Helicone
まとめ
Context Engineering を活用することで、AI agent の性能は大幅に向上します。
- 効率性:複雑タスクで最大 3倍のパフォーマンス向上
- コスト削減:API 使用料を最大 60% 削減
- スケーラビリティ:より複雑なタスクも処理可能
- 品質維持:大規模 context でも精度を確保
大切なのは、ユースケースに合わせた system design と、実際の metrics に基づく継続的な monitoring & optimization です。